这篇论文对之前的 A neural algorithm of artistic style中的style transfer的加速版本,同时也是一种进行风格转移的通用框架。常见的例如降噪,超分辨率和着色等任务其实都可以看作是一种图像转换任务,一种解决方法便是通过训练一个feedforward 卷积神经网络,通过有监督方式进行训练,但是之前的loss只是利用像素级别的loss进行训练,这种方式和image parsing的训练方式比较相似。但是在图像生成任务中,如果仅仅使用像素级loss,则无法在语义层面对生成图像进行约束,所以基本思路就是在像素和语义两个层面进行约束。具体而言我们希望用tyle图像中的纹理细节去代替原来图中的纹理细节。
这篇文章中的网络框架如下: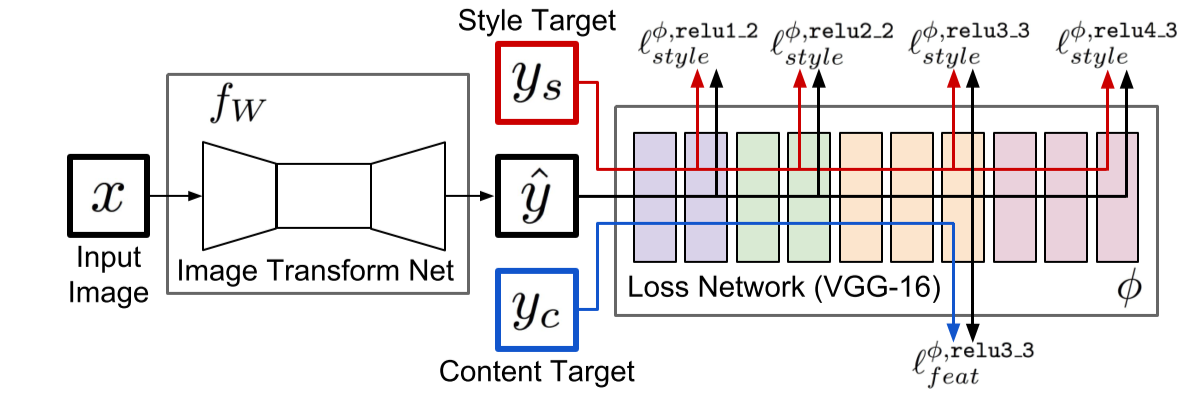
基于chainer的实现chainer_art_style.
Image Transform Net 为一个autoencoder,设计细节为不使用polling层,仅仅使用卷积核学习采样能力,然后中间使用ResNet Blob进行特征提取,后面采用Dcov层进行图像再生,每个卷积层后面加ReLU和BatchNorm层,最后一层采用tanh激活函数对输出进行约束然后转换到图像空间。loss采用已经再imagenet上训练好的vgg16模型进行loss的计算,其中relu1_2,relu2_2,relu3_3,relu4_3作为计算style_loss,relu3_3作为content loss,至于如何这样选择,是通过观察图片再各层的特征图的特点决定的。
content loss的计算方式为
style loss的计算方式如下
如果把$\phi_j(x)$转换为shape为
那么
另外还有像素级loss和total variation regularizer loss用于空间平滑。
当然这篇文章还介绍了如何使用这个框架进行超分辨率的研究,篇幅有限下次再及进行介绍吧。